The Uneven Distribution of AI's Impact

Lately, I’ve been marinating on William Gibson’s oft quoted “the future is already here - it’s just not evenly distributed.” Anthropic’s Economic Index report from last month exemplifies this idea:

The figure shows that computer and mathematical disciplines disproportionately over-index in AI usage (by a factor of >10x relative to representation among US workers). Focusing specifically on white collar jobs, my overarching question is: If usage is any indication of impact, why does AI appear to have such an uneven impact by industry?
I’ll first address two common explanations, before offering my two cents:
The models are not “smart” enough for broader tasks
I am doubtful. Without dismissing the limitations of benchmarks, generalist reasoning performance (i.e. MMLU-Pro) and competitive math performance (i.e. AIME 2024) of recent models are already inline or superhuman compared to experts’. It seems unlikely that these reasoning capabilities are domain specific and non-generalizable:
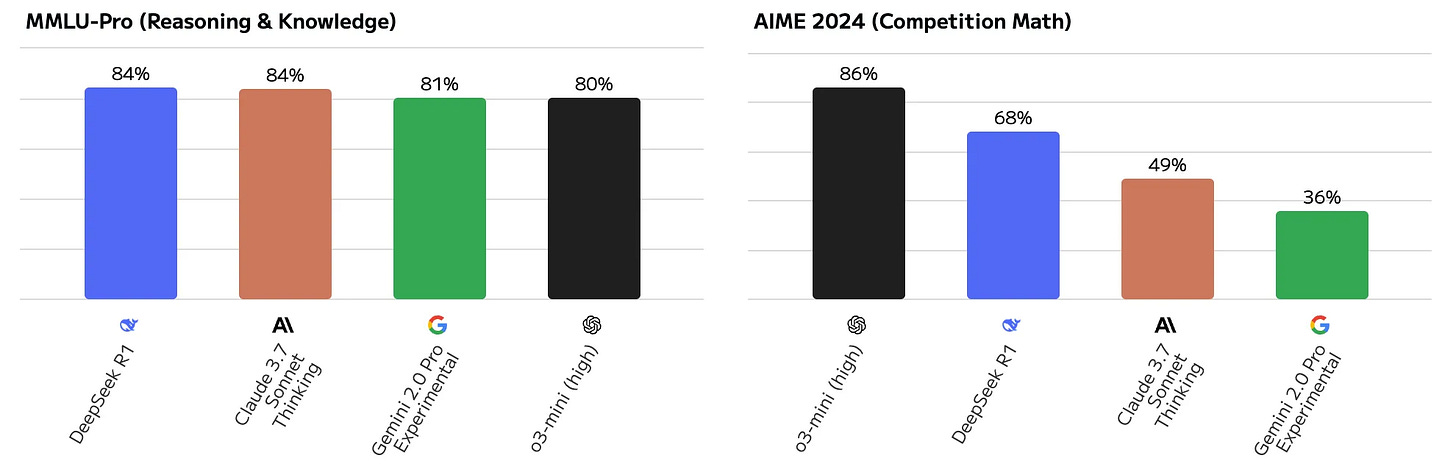
MMLU-Pro & AIME 2024 Accuracy by Model (Artificial Analysis)
Coders are closest to the space, and therefore earliest to catch on to adoption
This is true. As another confounding factor, Anthropic’s user base biases to developers. The AI household name is OpenAI’s ChatGPT, while Anthropic’s Claude is more known for its coding capabilities.
However, this explanation is inadequate. AI is already widely disseminated (i.e. ChatGPT alone has 400M WAU, while all major AI labs offer free tiers with generous model capabilities). Yet, we still haven’t seen a “GitHub Copilot moment” (released in 2021) for most industries, let alone the benefits of more recent advances from the likes of Cursor, Windsurf, and Claude Code.

My hypothesis: Underwhelming impact outside of math and coding is primarily attributable to 1) the interface mismatch between AI and common white collar workflows, 2) the ambiguity of a workflow’s correctness and 3) the real world side effects:
Interface mismatch
The native interface for AI models is the consumption and production of (primarily) text tokens; the models are trained mostly from readable text on the internet and post-trained in the same medium.
These text tokens align well with code, the medium of software engineering (indeed, it’s directly trained on code).
By contrast, most white collar workflows occur in the Graphical User Interface (GUI), but using GUIs is not natural to AI models because there is no organically accruing training data for usage of visual interfaces. Even moderately complicated workflows span multiple non-standardized applications, further complicating interactions. Moreover, even if GUIs produce textual artifacts (i.e. Excel’s .xlsx files) like code, these files are idiosyncratic to individual applications and their logic is often opaque (i.e. closed source XML encoding for .xlsx).
This interface mismatch likely explains why Copilot for Microsoft 365 and Gemini for Workspace have lacked traction. In an ideal world, we would have a direct mapping between AI’s textual tokens and the GUI experience, but the two mediums are fundamentally incompatible. The prevailing approach has therefore been to graft AI capabilities trained on curated internal code specific to an application into the user interface, leading to a subpar experience.
One mitigation that may popularize is “computer-use models” trained on collected GUI usage trajectories, such as OpenAI’s CUA or Claude 3.7 Sonnet. However, I remain skeptical of result quality from this approach given the relative inefficiency for AI to navigate a visual interface: The GUI experience is an affordance designed to make working with computers easier for humans. To force an AI model to abandon a more efficient medium (i.e. textual commands) to work as an overlay over this affordance is regressive.
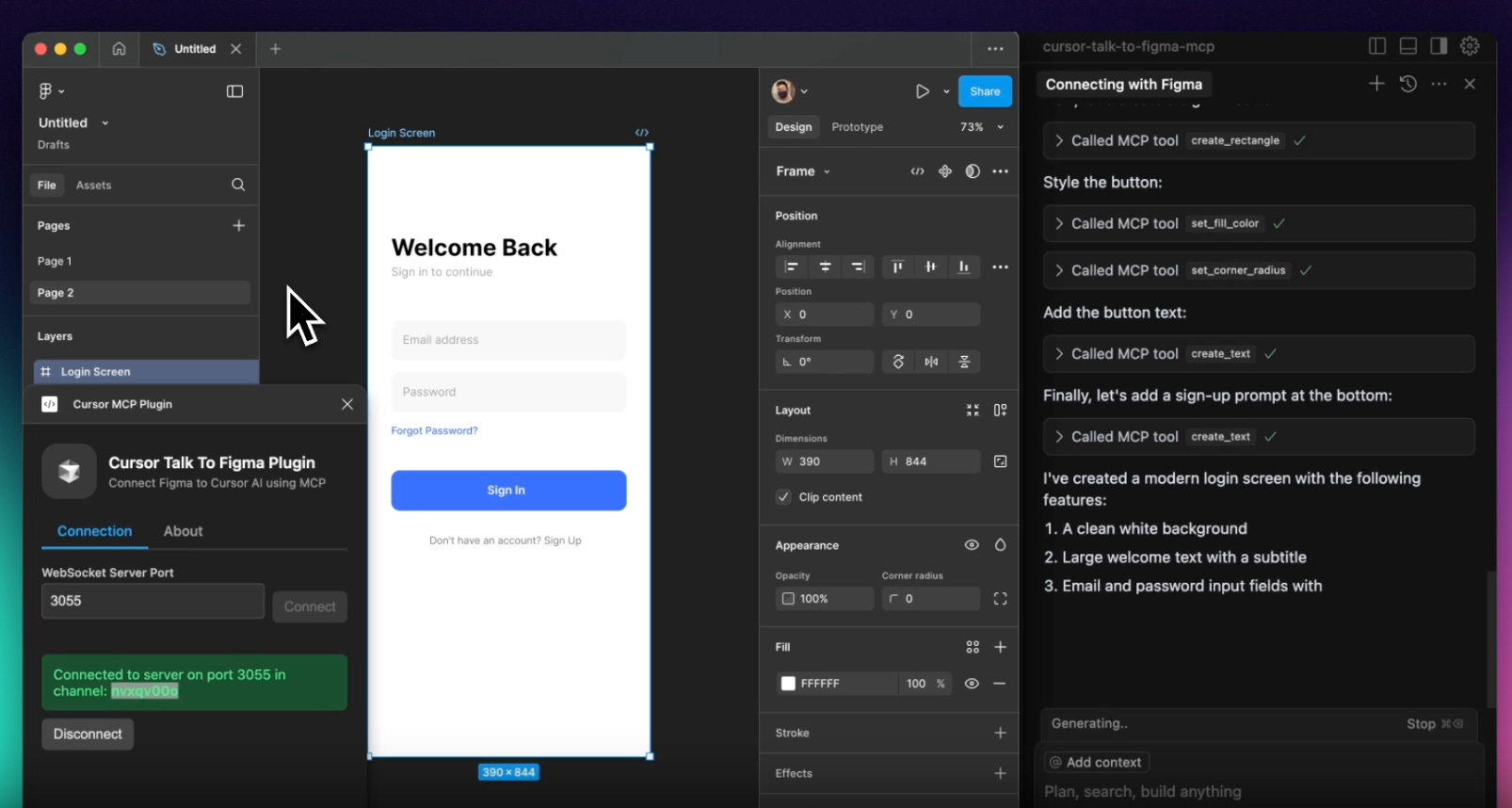
A more promising first step in this direction is Model Context Protocol (MCP), a standardized API standard for LLMs to work with external tools, including traditional GUI-based software like Blender and Figma. The results have been impressive. However, behind the scenes the MCP servers are still reliant on a code-based interface necessarily provided by software vendors, such as Blender’s Python API and Figma’s Plugin API, respectively:

Cursor editor using MCP to create a Figma mockup (Sonny Lazuardi)
Ambiguity of Correctness
The key driver of AI models’ ability to produce “intelligent” answers is our ability to define correctness during training. Reinforcement learning, which underpins state-of-the-art reasoning models, underscores this idea: Given a question and a model response, the training procedure rewards responses that are designated “correct” and penalizes responses that are “wrong” (in fact, it can be shown that the even the next token prediction task used for pre-training LLMs is itself a special case of reinforcement learning).
Clear definitions of correctness align well with coding, wherein we define correctness as the ability for code 1) to compile and 2) to pass unit tests, giving us two avenues to optimize model performance:
Generate large volumes of quality synthetic data by a process known as rejection sampling: For any given problem, generate many candidate responses, discarding incorrect responses as verified by our unit tests. By training on this synthetic data, a model can copy only “good” coding behavior.
Without giving the answer of a problem directly to the model, allow the model to develop the behavior needed to pass our unit tests by trial-and-error through thousands of iterations per problem - reinforcement learning.
On the other hand, correctness is often subjective for white collar tasks. For example, let’s say that we wish to automate cold emails to potential customers: What is a “good” email? There is often no clear objective definition that we can verify using a rule-based metric compared to the coding domain.
Real World Side Effects
Although correctness is difficult to define for each task, sometimes we can link correctness to a higher level proxy metric, but many workflows here run into the problem of side effects.
Continuing with our cold email example, perhaps we can define correctness through prospects’ response rate (i.e. a higher response rate is more correct)? There are two challenges associated with this approach:
Unlike testing for correctness in coding, which can be done in a sandboxed environment for millions of trials with no recourse, each trial requires an actual email to be sent to a prospective customer (imagine the negative impact of spamming prospects). In other words, we may encounter unintended real-world consequences for each trial in our hypothetical email workflow, limiting the number of trials that can realistically be done if we use an AI model to optimize a task.
Of all the things written in an email, how do you know what increased or decreased conversion? In reinforcement learning, we call this the credit assignment problem, and it’s exacerbated as we limit the number of trials we can run.
I believe that all three problems - 1) the interface mismatch, 2) ambiguity of correctness, and 3) real world side effects - need to be adequately addressed for AI to maximize its impact broadly.